Organizace, které existují již mnoho let, mají rozsáhlé soubory obsahující formální a právní dokumenty. Příkladem mohou být notářské zápisy a také nájemní smlouvy, smlouvy o pronájmu, obchodní podmínky a další podobné typy smluv mezi podniky nebo veřejnými subjekty.
Postupem času se společnosti vyvíjejí a získávají nové zákazníky, což způsobuje, že se jejich archivy ještě více rozrůstají. To je důvodem k obavám mnoha organizací v odvětví telekomunikací, energetiky, teplárenství a vodovodů a kanalizací. V závislosti na konkrétním případě vedou svou dokumentaci buď zcela v papírové podobě, nebo je digitalizována pouze její část.

Pro zajištění efektivity nouzových i běžných obchodních operací musí být vyhledávání dat rychlé a snadné. Toho je možné dosáhnout udržováním databáze s kategorizovanými a strukturovanými daty, která umožňuje rychlý přístup ke konkrétním informacím nebo určitému souboru dat. Digitální databáze výrazně usnadňuje analýzu a interpretaci dat i vytváření zpráv. Je mnohem lepší než papírový archiv nebo jednoduché digitální úložiště, které využívá optické rozpoznávání znaků ke čtení naskenovaných dokumentů. Papírové archivy a jednoduchá digitální úložiště umožňují vyhledávat konkrétní informace, ale jejich nestrukturovanost činí práci s daty pomalou a náročnou.
Z toho vyplývá několik otázek: Jak efektivně přesunout data z papírových dokumentů do strukturovaných databází? Existuje způsob, jak tento proces zlepšit?
Jak se přenášejí data z dokumentů do databáze?
Odpověď na tuto otázku je obvykle velmi snadná a mnohem méně efektní, než bychom očekávali.
Zadávání dat provádí člověk, často někdo najatý pouze za tímto účelem. Zkopíruje klíčové informace z dokumentů a ručně je zadá do příslušných sekcí databáze. Údaje obvykle zahrnují data, čísla a typy smluv, jakož i čísla rejstříků případů a čísla pozemkových knih. Data přesunutá do databáze lze využít v mnoha odděleních společnosti (například v zákaznickém servisu), což výrazně zvyšuje kvalitu práce.

Pokud není dokumentů mnoho a zadávání dat netrvá příliš dlouho, neměl by být tento proces extrémně náročný (i když je stále zdlouhavý). Na druhou stranu, zejména velké, zavedené společnosti se potýkají s ohromným množstvím dokumentů a množstvím dat, které stále narůstá a je třeba je zadávat do databáze, takže v jejich případě může taková práce zabrat práci na plný úvazek. Proto je třeba, aby firma zaměstnávala člověka, jehož jediným úkolem je zadávat data z dokumentů do databáze.
Ruční zadávání dat způsobuje mnoho problémů:
Jak zlepšit proces sběru dat pro formální a právní papírovou dokumentaci?
Globema je známá tím, že provádí výzkumné a vývojové projekty, a proto jsme se rozhodli prozkoumat tento problém a najít lepší způsob, jak mohou firmy shromažďovat data obsažená v papírových dokumentech.
Naší odpovědí bylo využití algoritmů umělé inteligence a strojového učení (AI/ML) a automatizace procesu. Sáhli jsme zpět k našim zkušenostem s aplikací LocDoc, kde jsme umělou inteligenci použili ke klasifikaci dokumentů a čtení dat z technické dokumentace as-built.
Použili jsme podobné mechanismy AI/ML jako v řešení LocDoc, ale tentokrát jsme automatizovali proces čtení a zadávání údajů obsažených ve formálních a právních dokumentech do databází, které se již v organizacích používají. Tak vznikl systém iDoc.
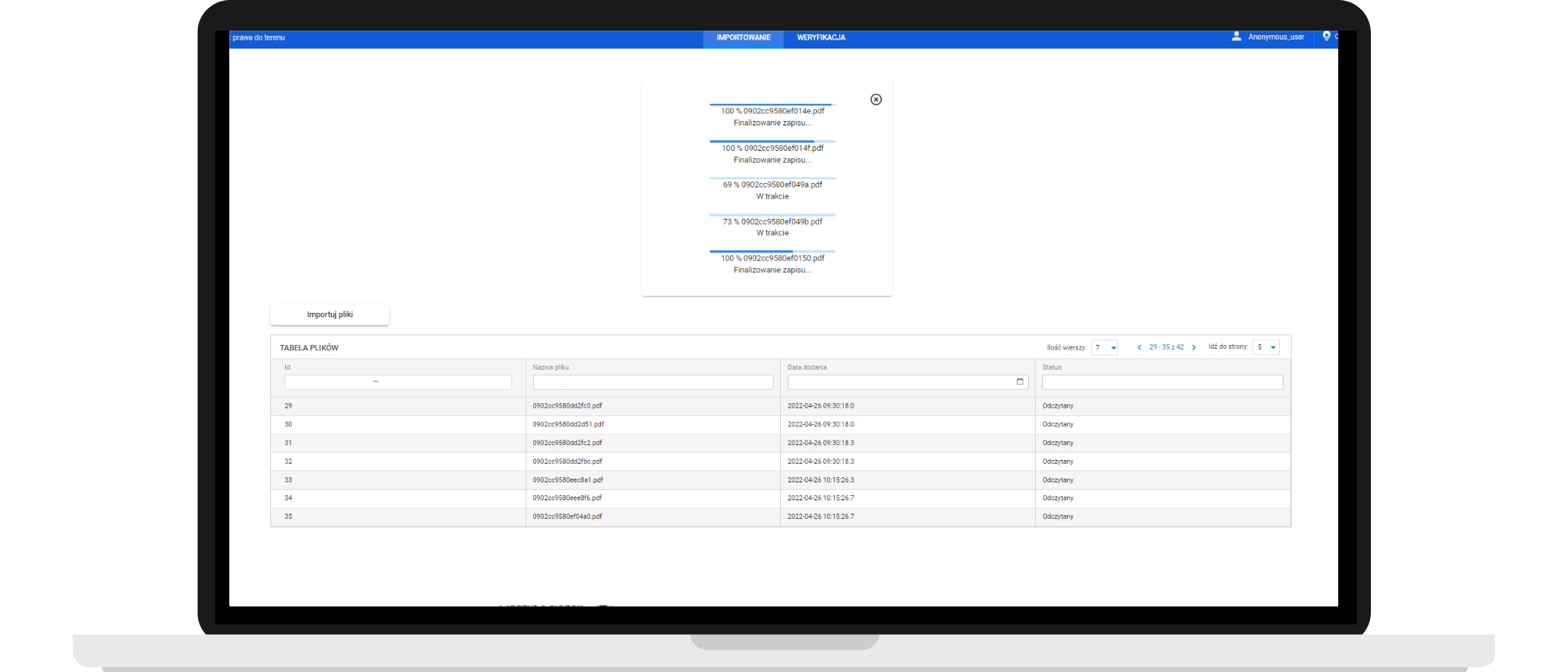
Klikněte pro zvětšení
Aplikace iDoc. Načtení naskenovaných dokumentů do systému – příprava na načtení dat a kategorizaci.
Jak funguje iDoc, řešení pro automatizovanou extrakci a klasifikaci dat?
Řešení iDoc využívá algoritmy AI/ML k automatickému čtení a klasifikaci dat obsažených ve formálních a právních dokumentech.
iDoc dokáže porozumět a číst formální a právní dokumenty, jako jsou:
- notářské listiny
- nájemní smlouvy
- nájemní smlouvy
…a další podobné typy listin mezi podniky nebo veřejnými subjekty. Každý typ dokumentu je jiný a obsahuje jedinečné informace.
Algoritmus přečte informace obsažené v dokumentu a rozpozná jeho typ (klasifikuje jej). Poté shromáždí informace a uloží je do databáze podle atributů (kategorií dokumentů a typů dat). Tuto databázi lze integrovat s jinými databázemi nebo systémy, které ve společnosti fungují.
Rozsah údajů obsažených ve smlouvách je velmi široký (obvykle asi 30 až 40 různých atributů a kategorií údajů v závislosti na typu dokumentu). Například:
- údaje o smluvních stranách (názvy společností, vlastníci, dodavatelé, advokáti, notáři atd.)
- adresní údaje (adresy všech smluvních stran, čísla pozemků atd.)
- doba trvání smlouvy
- data uzavření smlouvy
- identifikační čísla smlouvy, jako je např. číslo pozemku
- údaje o objektu
- informace o předmětu smlouvy
- platební údaje

Zpracování jednoho notářského zápisu (přečtení, zatřídění a vložení dat do databáze) trvá iDocu asi dvanáct sekund, což je pro člověka nedosažitelný výsledek. V průměru potřebuje člověk na zpracování šestistránkového dokumentu 11 minut.
Může umělá inteligence vykonávat veškerou práci a nahradit člověka?
Řešení společnosti Globema je založeno na algoritmech umělé inteligence, které dokáží číst a interpretovat data obsažená v papírových dokumentech, nicméně k zadávání dat do systému je stále zapotřebí člověka. Nejprve musí člověk do systému iDoc nahrát naskenované dokumenty (řešení dokumenty neskenuje, umí pouze číst a klasifikovat data ze skenů). A co je nejdůležitější, člověk musí ověřit správnost údajů, přičemž zvláštní pozornost musí věnovat fragmentům, které může počítač obtížně přečíst. Patří sem rukopis, razítka, rozmazané skeny, pomačkaný nebo potrhaný papír a také matoucí struktury, např. když jsou atributy zadány pomocí nepřímých informací.
Jak vypadá proces ověřování? Každý dokument se zobrazí na obrazovce se zvýrazněnými klíčovými frázemi rozpoznanými umělou inteligencí. Vedle něj je panel s poli vyplněnými těmito rozpoznanými údaji. Všechny objekty a atributy jsou uspořádány v logickém pořadí a jsou jim přiřazeny barvy, které odpovídají barvám použitým ke zvýraznění příslušného textu na naskenované stránce. Tento „barevný kód“ umožňuje uživatelům rychle vizuálně ověřit přesnost porovnáním údajů mezi oběma okny (dokumenty a bočním panelem).
Nakonec uživatel v případě potřeby zadá opravy a poté dokument, který právě ověřil, přijme.
Jak vidíte, lidský faktor není z procesu zcela vyloučen. Člověk stále hraje důležitou roli – možná ještě důležitější než dříve. Místo opakovaného mechanického kopírování se nyní může soustředit na ověřování dat a řízení celého procesu aktualizace databáze a udržování kvality dat.
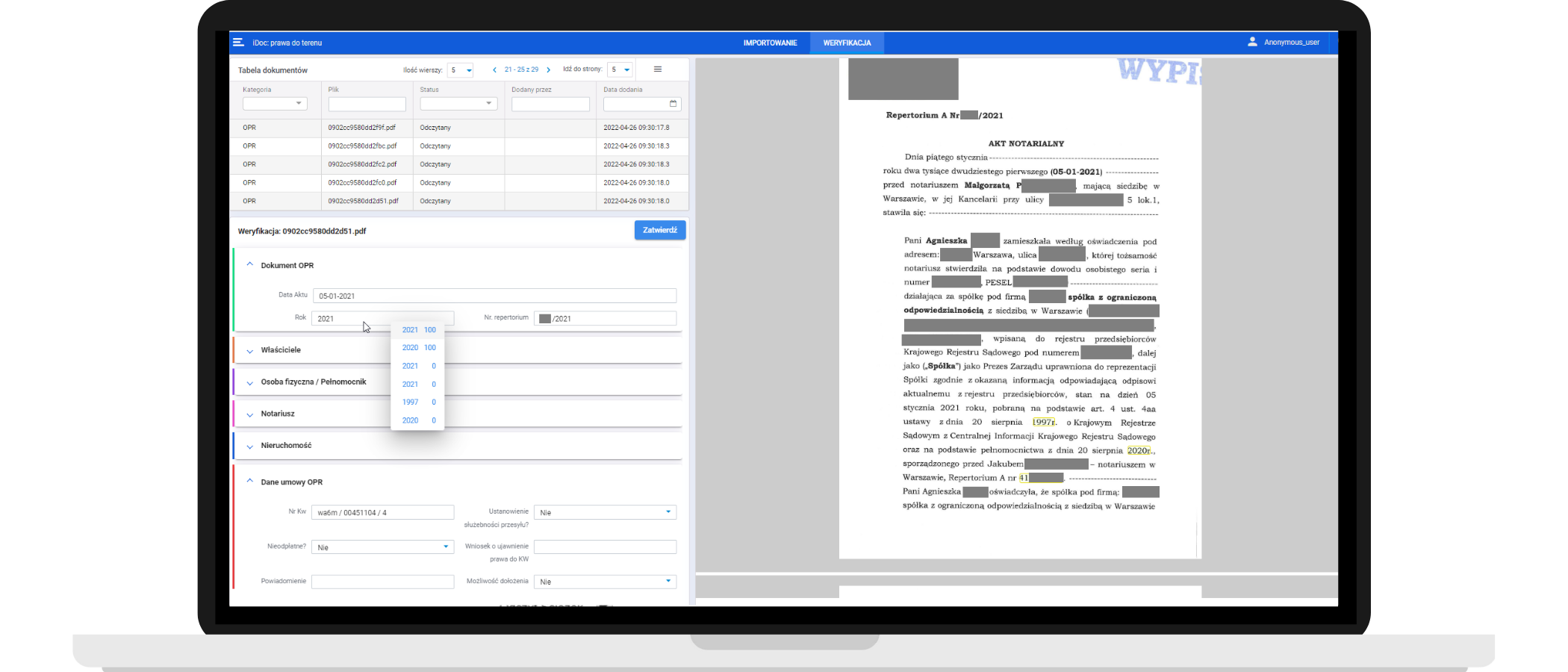
Klikněte pro zvětšení
iDoc. Pohled na panel pro ověřování dat. Můžete snadno zkontrolovat správnost načtených informací (umístěných v okně vlevo) a porovnat je se zdrojem v náhledu dokumentu (vpravo). Aplikace vám také dává na výběr kandidáty na zálohu hodnoty daného atributu a zvýrazňuje je v náhledu.
.
Statistické srovnání mezi lidmi a iDoc
Člověk dokáže v průměru během jednoho pracovního dne klasifikovat (rozpoznat, o jaký typ dokumentu se jedná) přibližně 3100 stran. Za stejnou dobu dokáže algoritmus umělé inteligence klasifikovat více než 30 000 stránek s přesností nejméně 96 %.
Podobně je tomu při čtení a zadávání konkrétních informací do databáze. Během jednoho pracovního dne může člověk přečíst a zadat do databáze přibližně 2000 atributů, zatímco stroj dokáže přesunout přibližně desetkrát více dat (což je asi 20 000 atributů!) při zachování přesnosti přibližně 85 %.

To znamená, že ačkoli algoritmy výrazně urychlují práci, nemohou zajistit 100% přesnost rozpoznávaných dat. Umělá inteligence může malé množství informací považovat za méně přesné a navrhnout uživateli jejich ověření. Proto je přesnost identifikace atributů definována jako poměr mezi všemi přesně rozpoznanými hodnotami atributů (těmi, které nevyžadovaly uživatelské opravy) a součtem všech atributů vyplněných algoritmy.
Jaké jsou výhody použití AI/ML pro klasifikaci dokumentů?
Přínosy automatizace procesu klasifikace dat lze jen těžko přeceňovat. Zvláště pokud přesun dat z dokumentů do systému zabírá ve vaší společnosti většinu času zaměstnance na plný úvazek a dokumentace neustále přibývá.
Využití AI/ML a automatizace procesu vkládání formálních a právních údajů obsažených v papírových dokumentech do digitální databáze znamená:
- 5-10krát rychlejší klasifikace a zpracování dat obsažených v dokumentech.
- přenesení břemene zdlouhavé práce z člověka na stroj a umožnění zaměstnancům soustředit se na dohled nad celým procesem.
- není nutné zaměstnávat osobu odpovědnou pouze za vyplňování databáze, což následně snižuje náklady na nábor a fluktuaci zaměstnanců
- digitalizaci dokumentů lze provádět mimo pracovní dobu a bez přestávek
- vyšší kvalita dat: automatizovaný proces není náchylný k únavě a rozptýlení – faktorům, které způsobují, že se lidé při zadávání dat dopouštějí chyb.
- úplnější databáze. Existuje mnohem větší šance, že se do systému přesunou všechny informace včetně historických údajů, než když je proces manuální.
Pokud přemýšlíte, zda je automatizace zpracování dat obsažených v papírových dokumentech a iDoc něco, co by pomohlo vaší firmě…
V příštím článku o automatizaci digitalizace dat budeme hovořit o implementaci naší služby v přední energetické společnosti.