Mnoho podniků čelí každý den stejnému problému: neorganizovaná, nestrukturovaná data, často uložená v archivech. Aby bylo možné data použít, je třeba je nejprve klasifikovat. Například, účetní doklady lze rozdělit na smlouvy, faktury, přijaté reporty, účetní příkazy a technickou dokumentaci sítě lze rozdělit na mapy, akceptační protokoly sítě, mapovací protokoly, protokoly o selhání sítě, protokoly o selhání stanic, karty technické kontroly atd. Proces klasifikace je však pro zaměstnance časové náročný, nákladný a frustrující. Jedním z řešení mohou být nástroje pro automatickou klasifikaci dokumentů, které jsou založeny na umělé inteligenci. Připravili jsme popis procesu automatické klasifikace a výsledků jednoho z našich experimentů strojového učení provedených v rámci projektu GlobIQ.
1. Sestavení klasifikátoru (modelu)
Sestavení modelu na základě souboru vstupních dat (souboru trénovacích dat). Příklady klasifikátorů (modelů): rozhodovací stromy, pravidla (IF … THEN …), neuronové sítě. Pro sestavení klasifikátorů můžeme použít empirický přístup založený na principu „učení a testování“, který nám umožňuje zvolit optimální model pro danou vstupní sadu.
Při klasifikaci textu je důležité filtrovat slova s nízkou informační váhou a indexovat text tak, aby byly získány odpovídající vektory, které je reprezentují. Pro tento úkol mohou být použity standardní vědecké knihovny, např. scikit-learn.
2. Testování modelu
Přesnost modelu lze ověřit následujícím způsobem: pro testovací příklady, pro které jsou známy hodnoty rozhodovacího atributu, jsou tyto hodnoty porovnány s hodnotami rozhodovacího atributu generovaného pro tyto příklady klasifikátorem. Správnost modelu ověřuje například míra přesnosti. Ta se vypočítá jako procento testovacích příkladů správně klasifikovaných pomocí modelu. Pokud je přesnost modelu přijatelná, může být model použit ke klasifikaci budoucích dat a předpovědi hodnot nových n-tic, pro které není hodnota rozhodovacího atributu známá.
Pro porovnání různých klasifikátorů během klasifikace více tříd, můžete použít například matice záměny.
3. Použití předem připraveného modelu k předpovídání neznámých hodnot
Pokud vezmeme v úvahu predikci nových dat, není hodnocení trénovacího souboru spolehlivé – nová data budou s největší pravděpodobností odlišná od trénovacího souboru.
Experimenty s klasifikací
Níže uvádíme výsledky jednoho z našich experimentů strojového učení, který byl realizován v rámci projektu GlobIQ. Experiment zahrnoval použití naivního Bayesovského klasifikátoru v řízeném režimu učení za účelem klasifikace projektové dokumentace.
Řízená klasifikace textu zahrnuje automatické přiřazování textů do sady předdefinovaných tříd (kategorií). Dokument může v závislosti na subjektivním hodnocení souboru patřit právě do jedné třídy (jedno-štítková klasifikace) nebo do více tříd (více štítková klasifikace). Variantou jedno-štítkové klasifikace je tzv. binární klasifikace, ve které je každý dokument přiřazen právě jedné množině nebo jejímu doplňku.
Kroky byly následující:
Ze scikit-learn knihovny jsme použili tyto klasifikátory:
- Random Forest Classifier
- Linear Support Vector Classification
- Multinomial Naive Bayes Classifier
- Logistic Regression
Pro vyhodnocení klasifikátorů jsme použili stejný trénovací soubor 470 dokumentů o známé kategorii (automaticky rozdělený na trénovací a testovací podmnožinu). Jako základní měřítko výkonu klasifikátoru jsme použili parametr “přesnost”. Což je poměr počtu správně předpovězených hodnot k celkovému počtu hodnot v testovací sadě.
Toto jsou výsledky pro jednotlivé klasifikátory:
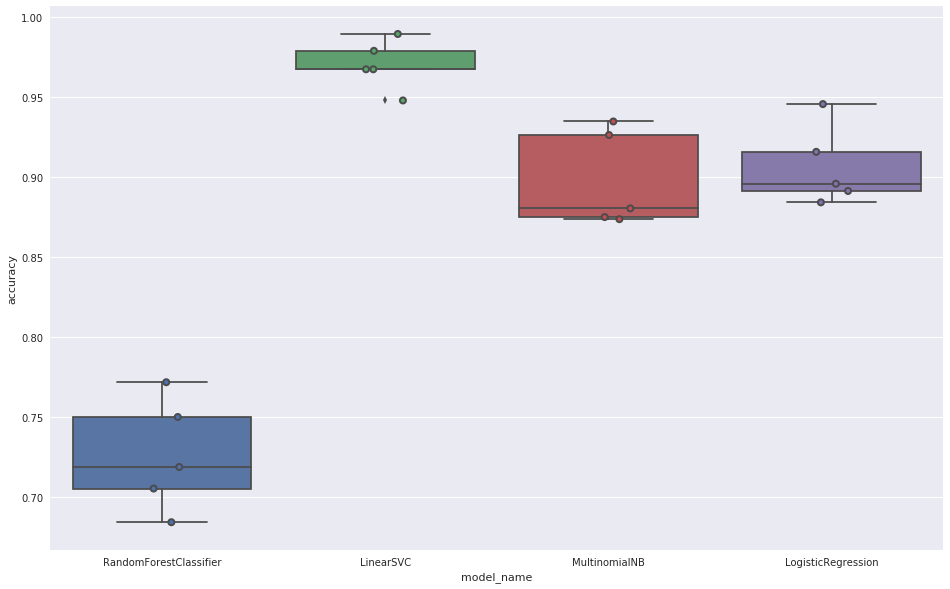
Nejlepších výsledků (0,975) bylo dosaženo pomocí klasifikátoru LinearSVC a ten byl později použit v experimentu.
Pro nejlepší nalezený klasifikátor (LinearSVC) jsme se simulovali klasifikaci souboru 6 272 PDF dokumentů se skeny (cca 24 000 stran A4). Pracovní postup byl následující:
- extrahování souborů JPG ze souborů PDF
- použití OCR pro načtení prostého textu ze souboru JPG
- použití klasifikátoru a predikce kategorií dokumentů
- porovnání předpokládané kategorie s kategorií určenou operátorem (správnou)
Výsledky experimentu byly následující:
| Kategorie | Dokumentů v kategorii | Nesprávně určených | Přesnost | Poznámky |
| 1 | 2,050 | 329 | 84.0% | Nízká kvalita skenů |
| 2 | 342 | 1 | 99.7% | |
| 3 | 2,340 | 13 | 99.4% | |
| 4 | 0 | 0 | - | Žádné dokumenty k dispozici na produkci |
| 5 | 1,539 | 13 | 99.2% | |
| Celkem | 6,272 | 357 | - |
Závěr
Dosažená přesnost kategorizace dokumentů byla velmi vysoká – pro 3 kategorie byla nad 99 %. Pouze u jedné kategorie byla přesnost 84 %. Klasifikace velkého množství dokumentů (10 000 – 20 000) byla dokončena během několika minut. Odhadujeme, že ruční prohlížení a klasifikace 10 000 dokumentů by trvala přibližně 10-20 dní. Výsledek experimentu dokazuje, že použití metod umělé inteligence je při klasifikaci dokumentů velmi užitečné.